JSON Configuration - Transforming through Merging and Patching
05 Apr 2020
JSON is a nearly universal standard for configuration files. From web servers to IoT, JSON is used to store settings and values to configure the behavior of systems. Good practice for complex systems dictates that we separate the concerns of our configuration into multiple files. This post talks about how to merge those files back together into a single representation that an application can use.
The techniques in this post can also be used to create a hierarchy of configuration files. This allows you to replicate (to a point) the inheritance mechanism found in object oriented programming languages. While an inheritance mechanism is overkill for a simple web server, many other applications (such as configuring physical products) could benefit from a hierarchical configuration design.
We’ll cover two main techniques: merging and patching. Merging is simple and very common, but suffers from some flaws that severely limit it’s applicability. Patching allows the programmer to completely and precisely specify the changes needed, but suffers from poor readability.
Why we’re talking about transforming JSON
Separating your configuration into multiple files based on scope is good design practice. It allows you to focus on just the settings that matter, while being able to ignore the values in non-relevant files. So we want to have multiple files to store the configuration in, but to use the stored values our program will need to determine which value in which file to use.
Consider a company making satellites. They have many different satellite types in many different orbits. Each configuration file has a number of properties that must be merged until we get to the final configuration for a product.
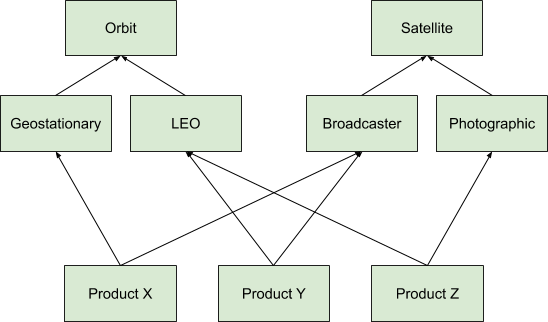
Here we have 9 different configuration files, each dealing with a part of this configuration. Sure, Product X has 5 different configuration files to merge. But consider the alternative: we would need to have a complete configuration file for every product, with all the duplication that entails. Designing a JSON hierarchy into your system is not for the simple cases, but for the cases where the application is already complex and you need to manage that complexity.
With the example out of the way, for the rest of this post we’re going to consider the theory of merging.
For our program, we want to use B to indicate the necessary changes in A to create the result R.
Each of the problems that I describe are problems of expressing intent: standard JSON does not have enough depth to represent anything but a collection of values. To do all possible transforms, JSON would need to have a mechanism for expressing operations. That’s where patching comes in. More on that later.
The absolute simplest option for transformation is merging. A merge will overwrite keys: save every key in dictionary B into a copy of dictionary A. This results in every duplicated key having the value from B, while preserving the non duplicated keys. Many different programming languages natively support this paradigm. Python merges dictionaries by {**A, **B}, while in Javascript it’s {...A,...B}.
The simple overwrite option might be sufficient for simple cases, but for complex configurations and settings it can quickly fail. Let’s look at the problems that can’t be solved with the standard JSON format.
Merging behavior depends on the data type. JSON supports strings, numbers, booleans, the null value, objects, and arrays. For the first four, it’s almost always a choice of replacement: the new value replaces the old. However, for objects and arrays, we have some more complex merging behaviors to consider.
Merging Problem #1: Key deletion
Merging does not allow for removal of keys. Consider for example the following configurations (A first, followed by B):
{
"w": 0,
"x": 1,
"y": 2
}
{
"x": 3,
"z": 4
}
The overwrite method is to simply merge the two dictionaries. Order maters, but you probably have a precedence preference. Start with A, and then iterate and write each key of B into A.
But let’s say you wanted B to indicate that key w should be removed. How would you mark that? null might work, except that it’s a valid JSON value so that means you can’t use it as a value for a setting. Whatever you do there will have to be some special notation.
Maybe REMOVE? Technically that would work, but it means that your JSON is no longer standard or parseable by a standard library.
{
"w": REMOVE,
"x": 3,
"z": 4
}
So problem #1 is how to remove a key when merging.
Merging Problem #2: Dictonaries
What should we do when we encounter nested dictionaries?
{
"w": {
"x": 0
}
}
{
"w": {
"y": 1
}
}
The overwrite method will ignore the nested dictionaries and simply replace the keys in A with the keys in B. In this case the result is just B.
Most programmers would probably want to recurse, and you end up with this:
{
"w": {
"x": 0,
"y": 1
}
}
Which is fine, until you get to a case where a recursive merge doesn’t make sense:
{
"animal": {
"type": "mammal",
"properties": {
"legs": 4
}
}
}
{
"animal": {
"type": "fish",
"properties": {}
}
}
Recursively merge with overwrite keys and we get:
{
"animal": {
"type": "fish",
"properties": {
"legs": 4
}
}
}
In this case our resultant 4 legged fish is invalid. What we really want to do is recursively set properties on some, but not all keys.
Note that if we had a way to delete keys we could in theory delete legs and be ok. Unfortunately, from a software engineering perspective this creates a coupling between the two configuration files.
So, problem #2 is handling dictionary values. Do we only operate on the top level, or do we recurse? When do we stop recursing?
Merging Problem #3. The Big Problem. Arrays.
Arrays are the devils of JSON transformation. Pretty much everything about them presents an unsolvable problem: merging two arrays, adding elements, removing elements, inserting elements.
Merging Problem #3a: merging arrays
Let’s say we want to merge two arrays. They could be the same length or different lengths, both present issues. Our sample cases:
{
"w": [
{"x": 0}
]
}
{
"w": [
{"y": 1}
]
}
We have a few options here. We can replace entirely, which would just give us B in this case.
Alternatively, we can append B to A:
{
"w": [
{"x": 0},
{"y": 1}
]
}
Or we can merge each value by index:
{
"w": [
{
"x": 0,
"y": 1
}
]
}
Merging Problem #3b: add, remove, and reorder elements from array
Merging simply can not support fine grained actions on an array. There’s no way to annotate that an element from an array in B has some relationship to the array in A. At the very least we’d need a mechanism to indicate the action (add, remove, change) and a mechanism to indicate the location (by index or last).
Solutions
Let’s talk about how to solve this problem.
Patch Files
We have two fundamental options to choose from: merging and patching. We’ve discussed merging, and some of the problems, so let’s discuss patching. It’s pretty straight forward:
{
"w": 0,
"x": 1,
"y": 2
}
[
{"op": "replace", "path": "/x", "value": 3},
{"op": "add", "path": "/z", "value": 4},
{"op": "remove", "path": "/w"}
]
Results in
{
"x": 3,
"y": 2,
"z": 4
}
When B is a patch it’s simply a list of operations to perform on A. We can define pretty much any operation, and we can define the location that it operates on, so this method gives us the ultimate in flexibility. Unfortunately it also means that B no longer conforms to the same structure as A. Additionally, a complex patch file is much harder to learn and reason about.
How’s it Done in the Wild?
Let’s see what some popular open source frameworks do. We’ll start by investigating the specifications.
Official Specifications
Unfortunately the standards for this aren’t actually official yet. There are two proposed standards, one for merging and one for patching.
Yes, the very similar naming for these two specifications is terribly confusing.
JSON Merge Patch
JSON merge patch (RFC 7396) deals with how to take A and a similarly structured B and produce the result. Simple values are replaced, the null key means remove, and arrays are replaced entirely. For example:
{
"a": "b",
"c": {
"d": "e",
"f": "g"
},
"h": [1, 2]
}
{
"a":"z",
"c": {
"f": null
},
"h": [3, 4]
}
Results in
{
"a": "z",
"c": {
"d": "e"
},
"h": [3, 4]
}
JSON Patch
JSON patch (RFC 6902) “defines a JSON document structure for expressing a sequence of operations to apply to a JSON document.” This standard can do pretty much any modification of the original document A.
We saw an example of JSON Patch up above to handle some simple cases that merge can handle. Now let’s look at a more complex example that works with arrays:
{
"a": [1],
"b": [2, 4],
"c": [
{"d": "e"}
]
}
[
{"op": "add", "path": "/a/1", "value": 2},
{"op": "add", "path": "/b/-", "value": 5},
{"op": "add", "path": "/c/0/f", "value": "g"},
{"op": "remove", "path": "/b/0"}
]
Results in
{
"a" : [1, 2],
"b" : [4, 5],
"c" : [
{"d": "e", "f": "g"}
]
}
Sort of cool, but also much harder to look at the patch file and understand how it differs from the original A.
Software Projects In the Wild
Below are some examples of projects that have had to deal with the problem of transforming JSON.
- Node-convict (JS): recursive merge, arrays are merged by replacement.
- deepmerge (JS): arrays are merged by replacement or by merging at each index. Also supports a mechanism for custom merging depending on key name.
- node-config (JS): arrays are merged by replacement.
- nconf (JS): all top level keys are merged by replacement, no recursion.
- configparser (Python): Only supports string data types, so advanced merging is moot.
- Flask (Python): Merges based on top level keys.
- Django (Python): Merges based on top level keys.
- Kubernetes (PaaS): Supports both a custom merge mechanism and JSON merge patch merging. For the custom mechanism, every possible configuration path has a merge strategy that customizes how it’s merged.
- Postgresql (SQL):
||merges top level keys by replacement, no recursion. There are also specific operators for things like add, remove, replace, although none that can be represented in a JSON document. - Oracle (SQL): JSON columns can be updated by providing a merge patch document.
- MongoDB (NoSQL): Many different patch options, mostly an in house version of JSON patch. The user specifies the operations to perform using some extra syntax for searching in arrays and doing updates on one or more elements.
- JSON Schema (community specification): Merges by adding, never replacing. Explicitly not intended for complex solutions like hierarchies.
From this, it’s pretty obvious that the Python community has not given much thought to standardizing complex configurations. But besides that, it’s also clear that there isn’t a good solution to transforming JSON configuration files. Every software package has their own solution, some better or more flexible than others, but all unique.
My Conclusion
Which option to use certainly depends on the particulars of the configuration. Most web servers probably just have a few values to work with, so can get by with a simple recursive merge.
On the other hand, I’ve worked on projects that have very large and complex configuration files that need more complex merging capabilities. If it’s just a few values to change, JSON Patch might be the right way to go. But if it’s whole documents that need to be transformed it’s likely a custom mechanism like Kubernetes will be required. Regardless of the path chosen, careful consideration of how the transformation is applied is critical to avoid bugs in your configuration.